什么是zab
zab同paxos、raft一样也是一种协议,用来解决分布式系统中数据保持一致性问题。 zab全称:zookeeper atomic broadcast(zookeeper原子广播协议)。由名字很容易看出,zab是用于zookeeper的。 zab协议:是为分布式协调服务zookeeper专门设计的一种支持崩溃恢复和原子广播协议。
简单理解,崩溃恢复和原子广播可以类比成raft的节点挂掉重新选举和leader和follower节点之间的心跳检测。
zab有两种模式,恢复模式(选举)和广播模式(同步)。
zab选举模式类比mutli paxos,详细关于paxos原理介绍可参见paxos
- 当leader节点挂掉后,zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和follower之间具有相同的系统状态。
- 当ZooKeeper集群选举出leader同步完状态退出恢复模式之后,便进入了原子广播模式。所有的写请求都被转发给leader再由leader将更新proposal广播给follower。
为了保证事务的顺序一致性,zookeeper采用zxid(递增事务id)来标识事务。实现zxid的是一个64位数字。
- 其高32位为epoch:当前leader的标识,用来标识leader是否改变。类比etcd中leader的term(任期)。
- 其低32位为zxid:递增事务id。
zab角色与选举状态
zab角色
- leader:主节点,唯一。
- follower:工作从节点,能参竞选和投票。
- observer:进行日志备份从节点,不能参与竞选和投票。
zab状态
- looking:竞选状态。
- following:随从状态,同步leader状态,参与投票。
- observering:观察状态,同步leader状态,不参与投票。
- leading:领导者状态。
zab选举流程
大致选举流程如下:
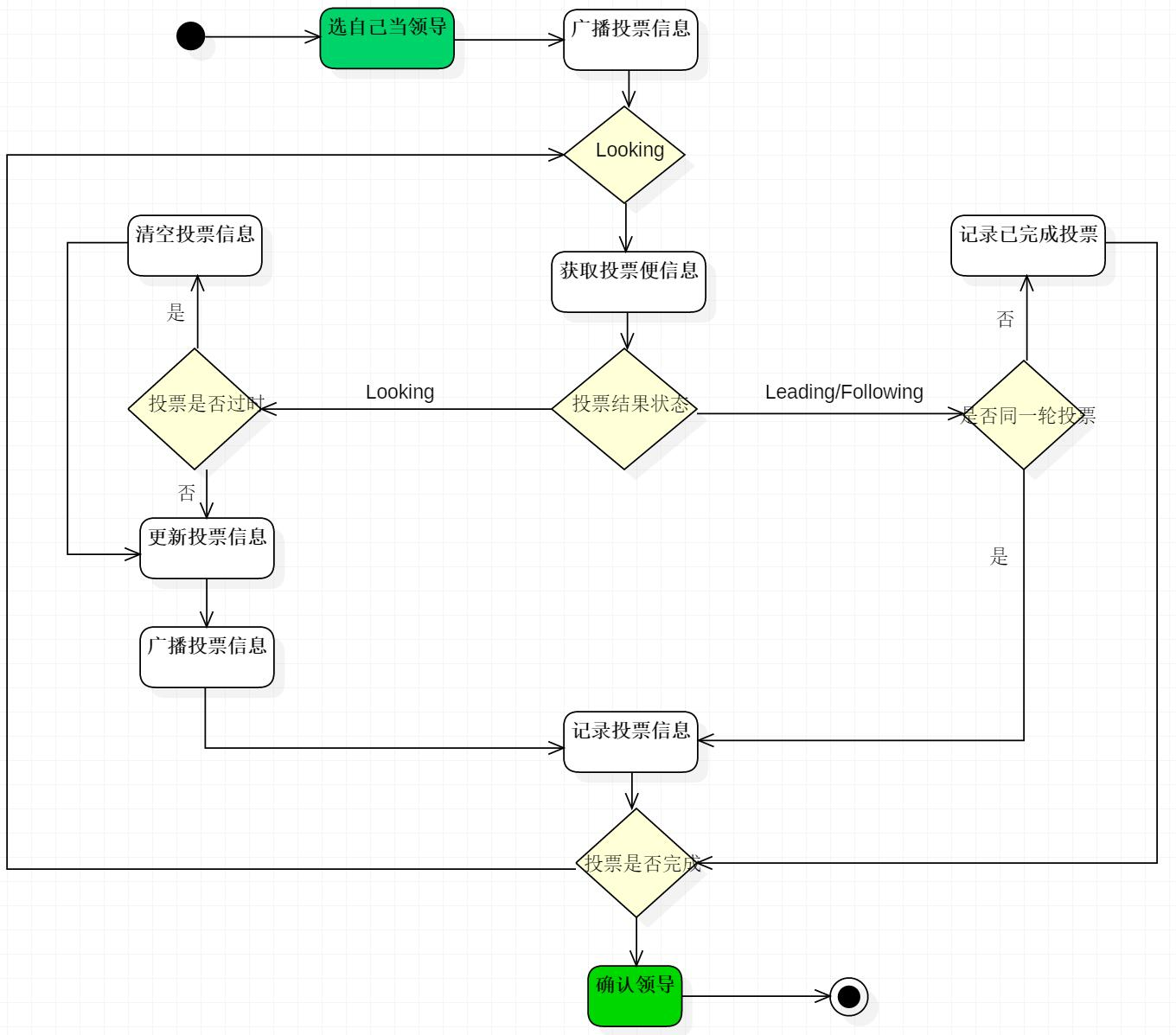
在不考虑节点数据和epoch等情况下,可视为全新部署的zookeeper集群,现有3台server,serverid为1-3顺序启动,选举过程:
- server1启动完成,server2和3还未启动完成,集群中没有leader,server1发出的消息未收到响应,server1为looking状态。
- server2启动,它与最开始启动的server1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的server2胜出,此时集群中3个节点中的两个投票给server2超过大多数,server2节点成为leader。
- server3启动,集群中有leader节点存在,自动成为follower。
当集群工作了一段时间后,都有各自的数据存在,此时集群中leader挂掉后的重新选举过程:
此时需要引入新的概念:
- 数据version:数据版本,最新修改的数据version就大
- 逻辑时钟:这个值从 0 开始递增,每次选举对应一个值,也就是说:如果在同一次选举中, 那么这个值应该是一致的;逻辑时钟值越大,说明这一次选举 leader 的进程更新,也就是 每次选举拥有一个 zxid,投票结果只取 zxid 最新的
选举标准:
- 逻辑时钟小的选举结果被忽略,重新选举。
- 统一逻辑时钟后version大的胜出。
- version一致的节点,serverid大的胜出。