1.Producer可靠性策略
选举算法有很多中如raft,zab,paxos,与 Kafka 实际执行情况最相似的学术刊物是来自微软的 PacificA,也是基于大多数原则,此处不深入介绍。略显不同的是kafka中有controller的概念,所有的broker向zookeeper中抢注/controller这个临时(EPHEMERAL)节点,第一个抢注成功的broker成为controller,在具备broker的责任同时管理kafka所有broker、partition以及replica变化。
/controller临时节点内容大致如下
1
{"version":1,"brokerid":0,"timestamp":"1529210278988"}
Producer可靠性策略
acks:此配置是 Producer 在确认一个请求发送完成之前需要收到的反馈信息的数量。 这个参数是为了保证发送请求的可靠性。以下配置方式是允许的:
acks=0,设置为0时producer发送消息后不会等待kafka服务器的确认返回。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。在这种情况下,服务器是否收到请求是没法保证的,并且参数retries也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。
acks=1,设置为1时producer发送消息后会leader节点将日志写入本地成功后不等待follower节点的确认反馈就给producer返回确认消息。该设置下回出现消息丢失。
acks=-1,设置为-1时(即all),发送消息后,leader节点会等待所有follower返回确认消息后才返回给producer确认消息。该设置下会出现消息重复。
以上三种策略需要根据应用场景评估。
消息丢失现象分析:当acks=1时,leader本地写入日志成功,返回给producer确认消息后,在与任意一follower节点同步过程均未完成时,leader节点挂掉,那么重新选举后,由于原follower节点中没有同步该条数据,而producer中确认该条消息发送成功,于是出现消息丢失。
消息重复消费分析:当acks=-1时,leader在与follower同步过程中挂掉,部分follower节点同步完成,而部分follower节点未完成,重新选举后会触发消息重新发送,导致该消息重复消费。
2.Producer分析
2.1)基本工作流程
kafka的producer发送消息采用的是异步发送方式。既然是异步那么至少包含2个线程。在producer的发送消息过程中使用了一个main线程和一个sender线程,另外还有一个线程RecordAccumulator(消息缓冲池)。
main线程:将消息发送给RecordAccumulator。sender线程:不断的从RecordAccumulator拉取消息发送到broker。
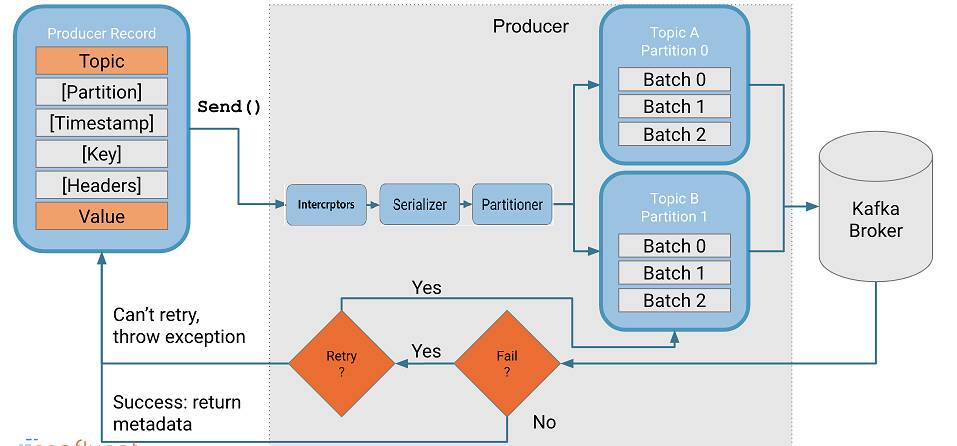
producer工作流程:
- 将待发送的数据封装成
ProducerRecord Object。 ProducerRecord Object经过拦截器Intercrptors。ProducerRecord Object经过序列化器serializer。ProducerRecord Object经过分区器partitioner。ProducerRecord Object发送到缓冲池RecordAccumulator。- sender线程不断轮询,从缓存池中拉取发送消息数据进行发送。
2.2)RecordAccumulatorkafka作用
kafka为了减少频繁发送消息建立tcp的消耗,每次发送一批消息数据,由batch.size控制。基于这个规则,kafka优先将每条消费消息发送至RecordAccumulator缓存起来,由sender线程每隔一段时间从缓存池中拉取一定大小的数据。间隔时间由linger.ms配置控制。
官方对linger.ms和batch.size给出的说明 linger.ms:producer 会将两个请求发送时间间隔内到达的记录合并到一个单独的批处理请求中。通常只有当记录到达的速度超过了发送的速度时才会出现这种情况。然而,在某些场景下,即使处于可接受的负载下,客户端也希望能减少请求的数量。这个设置是通过添加少量的人为延迟来实现的—即,与其立即发送记录, producer 将等待给定的延迟时间,以便将在等待过程中到达的其他记录能合并到本批次的处理中。这可以认为是与 TCP 中的 Nagle 算法类似。这个设置为批处理的延迟提供了上限:一旦我们接受到记录超过了分区的 batch.size ,Producer 会忽略这个参数,立刻发送数据。但是如果累积的字节数少于 batch.size ,那么我们将在指定的时间内“逗留”(linger),以等待更多的记录出现。这个设置默认为0(即没有延迟)。例如:如果设置linger.ms=5 ,则发送的请求会减少并降低部分负载,但同时会增加5毫秒的延迟。
batch.size:当将多个记录被发送到同一个分区时, Producer 将尝试将记录组合到更少的请求中。这有助于提升客户端和服务器端的性能。这个配置控制一个批次的默认大小(以字节为单位)。当记录的大小超过了配置的字节数, Producer 将不再尝试往批次增加记录。发送到 broker 的请求会包含多个批次的数据,每个批次对应一个 partition 的可用数据小的 batch.size 将减少批处理,并且可能会降低吞吐量(如果 batch.size = 0的话将完全禁用批处理)。 很大的 batch.size 可能造成内存浪费,因为我们一般会在 batch.size 的基础上分配一部分缓存以应付额外的记录。
- 若linger.ms到达,缓存池中数据超过一个batch.size大小,则sender拉取一个batch.size的数据发送给broker。
- 若linger.ms到达,缓存池中数据不超过一个batch.size大小,本次不拉取数据。
- 若再次到达linger.ms,缓存池中数据依然不超过一个batch.size,那么本次sender拉取全部数据发送给broker。
3.Consumer分析
3.1)消费端的两种消费模式
- push:broker向consumer推送消费消息。属于被动模式。
- pull:consumer主动向broker拉取消息消费,属于主动模式。
由于broker无法感知consumer的性能承载状况,pull的好处在于consumer可以主动根据自身消耗状态主动拉取数据消费,不会造成consumer的过载或者是空载问题。而push模式下broker在五感知的情况下不断的向consumer推送消息数据,无法达到集群consumer的处理平衡,很容易造成consumer的过载或者是空载情况。
3.2)consumer的工作流程
3.2.1) 首先从poll开始。(consumer拉取模式的api),消费规则如下:
- 一个partition只能被同一个ConsumersGroup的一个线程所消费。
- 线程数小于partition数,某些线程会消费多个partition。
- 线程数等于partition数,一个线程正好消费一个线程。
- 当添加消费者线程时,会触发rebalance,partition的分配发送变化。
- 同一个partition的offset保证消费有序,不同的partition消费不保证顺序。
Consumers api的用法:
1
2
3
4
5
private final KafkaConsumer<Long, String> consumer; // 与Kafka进行通信的consumer
consumer = new KafkaConsumer<Long, String>(props);
consumer.subscribe(Collections.singletonList(this.topic));
ConsumerRecords<Long, String> records = consumer.poll(512);
consumer,是一个纯粹的单线程程序,后面所讲的所有机制(包括coordinator,rebalance, heartbeat等),都是在这个单线程的poll函数里面完成的。也因此,在consumer的代码内部,没有锁的出现。
3.2.2) fetch 拉取数据
consumer从partition中拉取数据过程大致如下:
- 获取consumer的offset。
当consumer启动时搜先判断的是从什么地方开始拉取数据,是从头开始还是从上一次的offset位置开始拉取数据。consumer配置是从上一次offset位置开始时流程如下:
poll之前,给集群发送请求,让集群告知客户端,当前该TopicPartition的offset是多少。通过
SubscriptionState来实现, 通过ConsumerCoordinator`1 2
if (!subscriptions.hasAllFetchPositions()) updateFetchPositions(this.subscriptions.missingFetchPositions());
向Coordinator发了一个
OffsetFetchRequest,并且是同步调用,直到获取到初始的offset,再开始接下来的poll.(也就是说Offset的信息如果存在Kafka里,是存在GroupCoordinator里面)。consumer的每个TopicPartition都有了初始的offset,接下来就可以进行不断循环取消息了,这也就是Fetch的过程。 - 生成FetchRequest,并放入发送队列。
- 网络poll。
- 获取结果。
3.2.3)确认offset
consumer拉去消息消费后需要提交确认消费的offset,不提交和提交失败都会造成消息的重复消费。 kafka consumer offset提交方式支持两种:
- 自动提交:
enable.auto.commit,自动提交参数,kafka默认开启自动提交。auto_commit_interval_ms,提交间隔时间配置。自动提交kafka将按配置的固定间隔时间提交offset。 - 手动提交:用户手动维护提交,分为同步提交和异步提交。
同步提交:同步模式下提交失败的时候一直尝试提交,直到遇到无法重试的情况下才会结束,同时同步方式下消费者线程在拉取消息会被阻塞,在broker对提交的请求做出响应之前,会一直阻塞直到偏移量提交操作成功或者在提交过程中发生异常,限制了消息的吞吐量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
"""
同步的方式10W条消息 4.58s
"""
import pickle
import uuid
import time
from kafka import KafkaConsumer
consumer = KafkaConsumer(
bootstrap_servers=['192.168.33.11:9092'],
group_id="test_group_1",
client_id="{}".format(str(uuid.uuid4())),
enable_auto_commit=False, # 设置为手动提交偏移量.
key_deserializer=lambda k: pickle.loads(k),
value_deserializer=lambda v: pickle.loads(v)
)
# 订阅消费round_topic这个主题
consumer.subscribe(topics=('round_topic',))
try:
start_time = time.time()
while True:
consumer_records_dict = consumer.poll(timeout_ms=100) # 在轮询中等待的毫秒数
print("获取下一轮")
record_num = 0
for key, record_list in consumer_records_dict.items():
for record in record_list:
record_num += 1
print("---->当前批次获取到的消息个数是:{}<----".format(record_num))
record_num = 0
for k, record_list in consumer_records_dict.items():
for record in record_list:
print("topic = {},partition = {},offset = {},key = {},value = {}".format(
record.topic, record.partition, record.offset, record.key, record.value)
)
try:
# 轮询一个batch 手动提交一次
consumer.commit() # 提交当前批次最新的偏移量. 会阻塞 执行完后才会下一轮poll
end_time = time.time()
time_counts = end_time - start_time
print(time_counts)
except Exception as e:
print('commit failed', str(e))
finally:
consumer.close() # 手动提交中close对偏移量提交没有影响
异步手动提交offset时,消费者线程不会阻塞,提交失败的时候也不会进行重试,并且可以配合回调函数在broker做出响应的时候记录错误信息。对于异步提交,由于不会进行失败重试,当消费者异常关闭或者触发了再均衡前,如果偏移量还未提交就会造成偏移量丢失。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
"""
异步的方式手动提交偏移量(异步+回调函数的模式) 10W条消息 3.09s
"""
import pickle
import uuid
import time
from kafka import KafkaConsumer
consumer = KafkaConsumer(
bootstrap_servers=['192.168.33.11:9092'],
group_id="test_group_1",
client_id="{}".format(str(uuid.uuid4())),
enable_auto_commit=False, # 设置为手动提交偏移量.
key_deserializer=lambda k: pickle.loads(k),
value_deserializer=lambda v: pickle.loads(v)
)
# 订阅消费round_topic这个主题
consumer.subscribe(topics=('round_topic',))
def _on_send_response(*args, **kwargs):
"""
提交偏移量涉及回调函数
:param args: args[0] --> {TopicPartition:OffsetAndMetadata} args[1] --> Exception
:param kwargs:
:return:
"""
if isinstance(args[1], Exception):
print('偏移量提交异常. {}'.format(args[1]))
else:
print('偏移量提交成功')
try:
start_time = time.time()
while True:
consumer_records_dict = consumer.poll(timeout_ms=10)
record_num = 0
for key, record_list in consumer_records_dict.items():
for record in record_list:
record_num += 1
print("当前批次获取到的消息个数是:{}".format(record_num))
for record_list in consumer_records_dict.values():
for record in record_list:
print("topic = {},partition = {},offset = {},key = {},value = {}".format(
record.topic, record.partition, record.offset, record.key, record.value))
# 避免频繁提交
if record_num != 0:
try:
consumer.commit_async(callback=_on_send_response)
except Exception as e:
print('commit failed', str(e))
record_num = 0
finally:
consumer.close()
由于自动提交的不够灵活性,无法准确的判断是否执行完消费,Kafka提供了手动提交offset策略。手动提交能对偏移量更加灵活精准地控制,以保证消息不被重复消费以及消息不被丢失。同步和异步提交均有自己的不足。提出了同步+异步的混合提交方式,针对异步提交偏移量丢失的问题,通过对消费者进行异步批次提交并且在关闭时同步提交的方式,这样即使上一次的异步提交失败,通过同步提交还能够进行补救,同步会一直重试,直到提交成功。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
"""
同步和异步组合的方式提交偏移量
"""
import pickle
import uuid
import time
from kafka import KafkaConsumer
consumer = KafkaConsumer(
bootstrap_servers=['192.168.33.11:9092'],
group_id="test_group_1",
client_id="{}".format(str(uuid.uuid4())),
enable_auto_commit=False, # 设置为手动提交偏移量.
key_deserializer=lambda k: pickle.loads(k),
value_deserializer=lambda v: pickle.loads(v)
)
# 订阅消费round_topic这个主题
consumer.subscribe(topics=('round_topic',))
def _on_send_response(*args, **kwargs):
"""
提交偏移量涉及的回调函数
:param args:
:param kwargs:
:return:
"""
if isinstance(args[1], Exception):
print('偏移量提交异常. {}'.format(args[1]))
else:
print('偏移量提交成功')
try:
start_time = time.time()
while True:
consumer_records_dict = consumer.poll(timeout_ms=100)
record_num = 0
for key, record_list in consumer_records_dict.items():
for record in record_list:
record_num += 1
print("---->当前批次获取到的消息个数是:<----".format(record_num))
record_num = 0
for k, record_list in consumer_records_dict.items():
print(k)
for record in record_list:
print("topic = {},partition = {},offset = {},key = {},value = {}".format(
record.topic, record.partition, record.offset, record.key, record.value)
)
try:
# 轮询一个batch 手动提交一次
consumer.commit_async(callback=_on_send_response)
end_time = time.time()
time_counts = end_time - start_time
print(time_counts)
except Exception as e:
print('commit failed', str(e))
except Exception as e:
print(str(e))
finally:
try:
# 同步提交偏移量,在消费者异常退出的时候再次提交偏移量,确保偏移量的提交.
consumer.commit()
print("同步补救提交成功")
except Exception as e:
consumer.close()