使用redis面对高并发高TPS时比较常见的几个问题有:
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 缓存预热
- 缓存降级
- 缓存与数据库保持最终一致性
其中缓存击穿,缓存穿透,缓存雪崩又尤为常见和重要。redis与数据库保持数据一致也是我们必须要保证的。这里总结分析一下这几个常见问题的引发原因和常用解决办法。
1.缓存穿透
1.1)什么是缓存穿透?
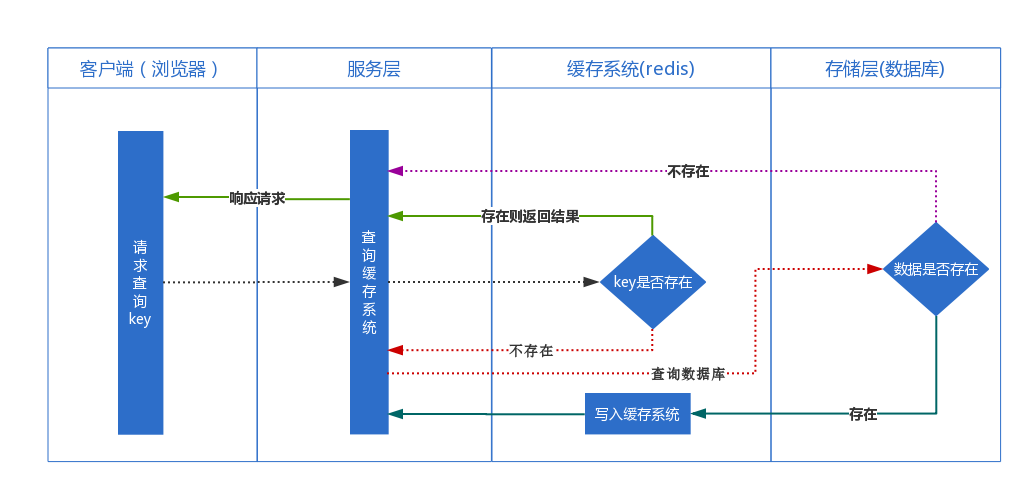 如上图这种设计模式下的处理流程
如上图这种设计模式下的处理流程
- 当server接收到来自client的请求后,首先查询redis,若在redis中命中结果则直接返回给server。若没有命中结果则会通知server没有命中。
- server接到redis返回没有命中的结果,则访问db进行查询。
- 在db中进行查询,若查询到结果则写入redis缓存并将最后查询到的结果返回给server。若查询不到结果则直接返回给server。
- server将结果返回给client。
查询的key内存没有数据,数据库也没有数据。也就是说查询一个不存在的key。这时在redis中无法命中,server将每次都需要访问数据库进行查询,而每次db查询结果都直接返回给server,并没有在redis中缓存,那么将导致这个不存在的数据每次请求都要查询存储层,当有人利用不存在的key频繁攻击我们的应用,并且流量很大的时候,数据库很有可能会挂掉,缓存也就失去了意义。
1.2)解决办法
常规解决办法
- 第一次查询时,将在数据库中没有查找到结果的key不直接返回给server,也先在redis中缓存。 当然,这种方法会存储许多无效的key,造成一定的redis资源浪费。需要和有效的key设置进行不同的有效时间来减少无效key的占用。
- 更为推荐的办法:使用布隆过滤器拦截,将所有存在的key使用布隆过滤器保存起来,在请求资源之前,先在控制层去查询这个key在布隆过滤器中是否存在。不存在则直接丢弃请求,减轻存储层的压力。这种方式适合数据相对固定,实时性低的场景,当然空间利用的也比较少。
布隆过滤器:一种多哈希函数映射的快速查找算法。它可以判断出某个元素肯定不在集合里或者可能在集合里,即它不会漏判,但可能会误判。这里不做详细说明。
2.缓存击穿
2.1)什么是缓存击穿?
与缓存穿透十分类似,只是当key在redis中失效后,某一时间server接收到来自client大量的该key的请求。在这一时间大量的server查询在redis中没有命中,则访问数据库,造成数据库某一时间的压力过大。
2.2)解决办法
加锁即可,单机部署使用互斥锁,分布式部署使用分布式锁。
3.缓存雪崩
3.1)什么是缓存雪崩
当某一时刻redis出现大面积的key失效,或者redis重启。这种情况我们成为缓存雪崩。缓存失效时的雪崩效应对底层系统的冲击非常可怕。
3.2)解决办法
- 从redis key的失效时间上避免:对不同场景和重要程度的key设置不同的过期时间。甚至是相同类型的key也设置不同的过期时间。
- 从提高redis的可用性上避免:搭建redis高可用集群,避免redis挂掉。
4.缓存预热
缓存预热很好理解,从字面上就可以看出,在启动前先将活跃数据加载到redis中,当然只是部分数据。加载完成后再对外提供服务。
关于热点数据统计,可以采用nginx访问量上报,或者市strom从kafka中消费数据,实时统计出每个商品的访问次数,访问次数基于LRU内存数据结构的存储方案。还能有其他很多的统计方案。
5.缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。降级的最终目的是保证核心服务可用,即使是有损的。
6.如何保证缓存与数据库的数据一致性
现有一条数据id=1, name=aa存在缓存与数据库中。现将name更新为bb,如何更新保证缓存与数据库数据结果一致?
- 错误方式一:先更新redis再更新数据库过程中数据库挂了和先更新数据库再更新redis过程中redis挂了都讲会导致最终两者数据不一致。
- 错误方式二:使用多线程,一个更新缓存一个更新数据库,会因网络延时的不一致性导致脏数据或是数据不一致。
正确方式如下:
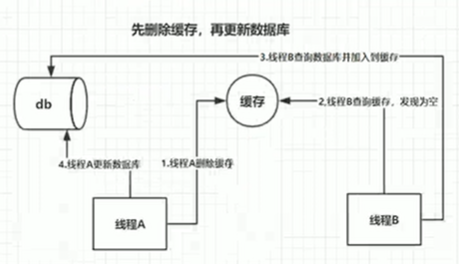 先删除缓存中数据再更新数据库。当收到请求查询缓存时,由于没有命中将会到后端数据库中进行查询,查询到结果返回后再添加到缓存中。最终达到数据库和缓存数据一致。
先删除缓存中数据再更新数据库。当收到请求查询缓存时,由于没有命中将会到后端数据库中进行查询,查询到结果返回后再添加到缓存中。最终达到数据库和缓存数据一致。