redis的常见搭建模式,按照发展模式排序(从客户端分区方面讨论,代理分区方案Twemproxy等先不列举):
- 单点搭建
- 主从模式
- 哨兵模式
- cluster模式 单点搭建模式不做过多分析,现在互联网的应用场景下,为了解决单点模式存在的弊端,如单击吞吐,并发,流量等问题,需要构建高可用的模式。
1.主从模式
有一主一从,一主多从,多主多从等等,即一个或者多个实例,一个或者多个slave实例。(后续集群的模式就是从多主多从演变的) 主从模式简单的来说就是主节点来工作,其余节点当作备份,在主节点挂掉的时候可以切换为从节点继续工作。 主从模式有两个作用:
- 上面说到的备份作用
- 另外一个作用,可以实现负载均衡和读写分离。大量的redis访问,在这种模式下可以将大量查询请求分配到从节点。避免主节点处理过多。毕竟redis是单线程模型。 上述两点可以算是主从模式相对单点模式的优点。 主从模式缺点:
- 没有解决单机的容量问题、吞吐性能问题。
- 主机挂了之后从机切换为主机需要人为进行,无法自动切换。
2.哨兵模式
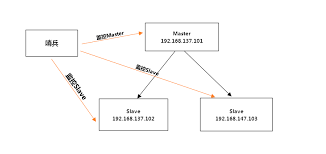 哨兵模式是主从模式的改进版本,模式架构和主从模式一模一样,具有组从模式的优点。与主从模式不同的是,哨兵模式具有选主的能力。在哨兵模式下,当master节点挂掉之后,可以从slave中选出一个作为master节点保证redis正常工作。
当使用哨兵模式的时候,客户端就不要直接连接Redis,而是连接哨兵节点的ip和port,由哨兵节点来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,哨兵节点就会感知并将新的master节点提供给使用者。
哨兵模式的优点:
哨兵模式是主从模式的改进版本,模式架构和主从模式一模一样,具有组从模式的优点。与主从模式不同的是,哨兵模式具有选主的能力。在哨兵模式下,当master节点挂掉之后,可以从slave中选出一个作为master节点保证redis正常工作。
当使用哨兵模式的时候,客户端就不要直接连接Redis,而是连接哨兵节点的ip和port,由哨兵节点来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,哨兵节点就会感知并将新的master节点提供给使用者。
哨兵模式的优点:
- 具备主从模式的优点
- 当主机挂掉后能自动切换从机成为主机。 哨兵模式的缺点:
- 切换过程中依然存在缓存无法使用的情况。
- 哨兵节点也存在挂掉的情况。
- 较难支持在线扩容。
3.集群模式
 redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。集群模式具备以下特点:
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。集群模式具备以下特点:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 失效判断同样按照大多数原则,节点的fail是通过集群中超过半数的节点检测失效时才生效。
- 客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
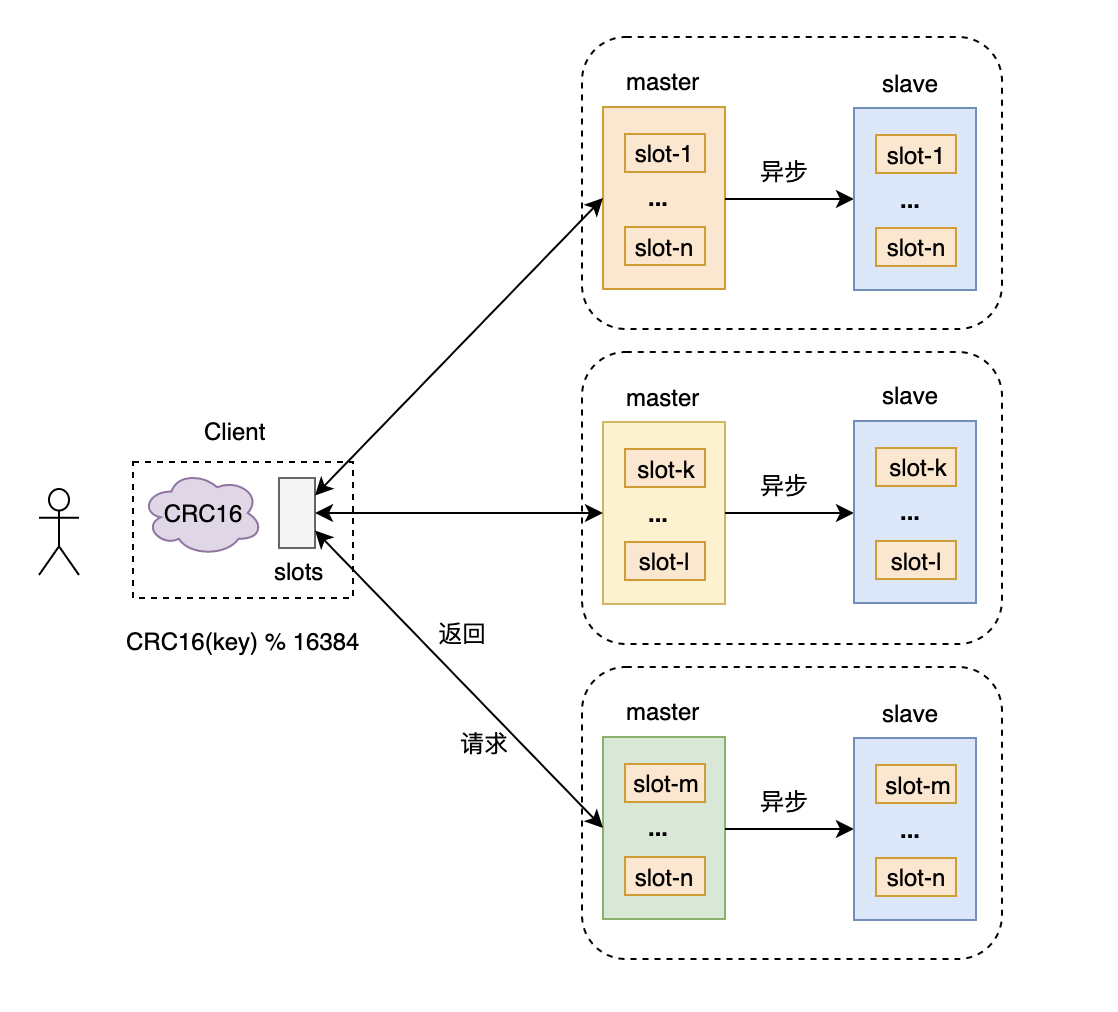
工作方式-哈希槽(slot): 在redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
关于哈希槽 数据分布的一种,包括节点取余分区,一致性哈希分区,虚拟哈希槽分区。 节点取余分区:使用特定的数据,如
Redis 的键或用户 ID,再根据 节点数量 N 使用公式:hash(key)% N计算出 哈希值,用来决定数据 映射 到哪一个节点上。如下:该方式的特点,简单,同时缺点也很明显,当发生分区数改变时,需要根据节点数重新计算分区映射,导致数据迁移。 一致性哈希分区:可以很好的解决 稳定性问题,可以将所有的 存储节点 排列在 收尾相接 的 Hash 环上,每个
key在计算Hash后会 顺时针 找到 临接 的 存储节点 存放。而当有节点 加入 或 退出 时,仅影响该节点在 Hash 环上 顺时针相邻 的 后续节点。如下虚拟哈希槽分区:redis cluster采用的数据分布策略。巧妙地使用了 哈希空间,使用
分散度良好的哈希函数把所有数据 映射 到一个 固定范围 的 整数集合 中,整数定义为哈希槽(slot)。这个范围一般 远远大于 节点数,比如Redis Cluster槽范围是0 ~ 16383。槽 是集群内 数据管理 和 迁移 的 基本单位。采用 大范围槽 的主要目的是为了方便 数据拆分 和 集群扩展。每个节点会负责 一定数量的槽,如图所示:当前集群有 5 个节点,每个节点平均大约负责 3276 个 槽。由于采用 高质量 的 哈希算法,每个槽所映射的数据通常比较 均匀,将数据平均划分到 5 个节点进行 数据分区。Redis Cluster 就是采用 虚拟槽分区。
- 节点1: 包含 0 到 3276 号哈希槽。
- 节点2:包含 3277 到 6553 号哈希槽。
- 节点3:包含 6554 到 9830 号哈希槽。
- 节点4:包含 9831 到 13107 号哈希槽。
- 节点5:包含 13108 到 16383 号哈希槽。 由于从一个节点将 哈希槽 移动到另一个节点并不会 停止服务,所以无论 添加删除 或者 改变 某个节点的 哈希槽的数量 都不会造成 集群不可用 的状态.
这种模式下,写入不可用的概率为:小集群中所有机器都宕的概率小集群宕机的时间段落点随机到该小集群分配落点的概率。伴随集群机器数量的增加能大大减少出现不可用的概率,确保高可用的能力,以该模式部署能保证可用度到99%。大大提高redis的可用性。
集群模式优点:
- 大大提高可用性,横向看,每个集群的master节点都对应有slaves,master挂掉后,新master会从slaves中选举出来;纵向看,每个集群可以手动扩容和缩容,添加减少master节点的数量;
- 支持更大规模的容量,采用分片的思想,两层抽象;key被分布到固定数量的slots中,集群masters各服务一部分slots,横向扩容master节点,可以支持更大容量的key;
- 提高吞吐量和性能,分片后的,客户端直接计算出key对应slot所在的master节点,直接访问目标master,实现了分布式,从而提高集群整体吞吐量;
集群一致性: (引用一致性) Redis集群中的epoch有两种:currentEpoch 和 configEpoch。
- currentEpoch(整个集群) currentEpoch代表了整个集群的拓扑版本信息。初始化的时候从0开始,如果节点接收到来自其他节点的包,发送者的currentEpoch大于当前节点的currentEpoch,当前节点就更新 currentEpoch为发送者的currentEpoch。当前currentEpoch只用于slave的故障转移流程。 slave发现其master下线,就会试图发起故障转移流程。首先增加currentEpoch的值,然后向所有节点发起拉票请求。其他节点收到包后,发现发送者的currentEpoch比自己的大,就会更新自己的currentEpoch,并投票。
- configEpoch(单个分片内 master+slaves)
configEpoch代表了单个节点配置(所负责的slots)的版本信息。master对外通告其所负责的slots列表,会对应一个configEpoch,所有slave的configEpoch与之一致。一个节点如果收到两个master同时宣称冲突的slot映射消息,就会分别判断两个消息中的configEpoch,并相信更大configEpoch消息中的映射关系。
- slave发起选举,成功当选后,会试图替代其已经下线的旧master
- slave增加它自己的configEpoch,使其成为当前所有集群节点的configEpoch中的最大值
- slave向所有节点发送广播包,强制其他节点更新相关slots的负责节点为自己
参考文章
数据分布引用和Codis, Twemproxy参考深入剖析Redis系列(三) - Redis集群模式搭建与原理详解